背景
Pandas 对于Pythoner的搞数据分析的来说是常用的数据操作库,对于很多刚接触Pandas的人来说会发现它是一个很方便而且好用的库,它提供了各种数据变化、查询和操作,它的dataframe数据结构和R语言、Spark的dataframe的API基本一样,因此上手起来也非常简单。但是很多新手在使用过程中会发现pandas的dataframe的性能并不是很高,而且有时候占用大量内存,并且总喜欢将罪名归于Python身上(lll¬ω¬),今天我这里给大家总结了在使用Pandas的一些技巧和代码优化方法。
1.使用Pandas on Ray
Pandas on Ray 主要针对的是希望在不切换 API 的情况下提高性能和运行速度的 Pandas 用户。Pandas on Ray 实现了Pandas 的大部分API 功能,可已作为Pandas的一个子集,其主要是利用并行化进行加速。
Pandas on Ray 既可以以多线程模式运行,也可以以多进程模式运行。Ray 的默认模式是多进程,它可以从一台本地机器的多个核心扩展到一个机器集群上。在通信方面,Ray 使用共享内存,并且通过 Apache Arrow 实现零拷贝串行化,显著降低了进程之间的通信代价。
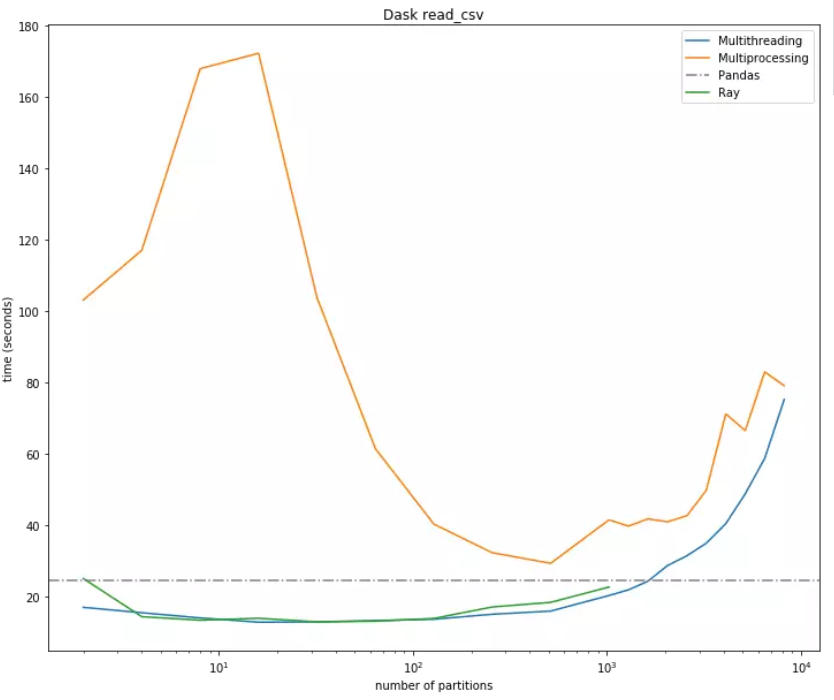
Ray 将根据可用内核的数量进行自动初始化,以一个1.8GB的全球健康数据为例
import ray.dataframe as pd |
输出结果:Pandas on Ray:
CPU times: user 48.5 ms, sys: 19.1 ms, total: 67.6 ms
Wall time: 68 ms
Pandas:
CPU times: user 49.3 s, sys: 4.09 s, total: 53.4 s
Wall time: 54.3 s
Pandas on Ray主要是通过并线化来加速,就和Spark一样,
1.1使用iterrows或者apply代替直接对dataframe遍历
用过Pandas的都知道直接对dataframe进行遍历是十分低效的,当需要对dataframe进行遍历的时候我们可以使用迭代器iterrow代替。
import pandas as pd |
输出结果loop directly...
Wall time: 29.2 s
loop with iterrows...
Wall time: 10.6 s
实验证明iterrow的效果在三倍以上。
1.2apply方法
dataframe是一种列数据,apply对特定的轴计算做了优化,在针对特定轴(行/列)进行运算操作的时候,apply的效率甚至比iterrow更高.
def loop_iterrows_test(df): |
结果输出func iterrows test...
Wall time: 12.3 s
func apply test...
Wall time: 3.8 s
apply函数比iterrow提高了4倍
1.3直接使用内置函数进行计算
Dataframe、Series具有大量的矢量函数,比如sum,mean等,基于内置函数的计算可以让性能更好,比如:time df['add'] = df['汽车百分比']+df['火车百分比']
输出结果Wall time: 546 ms
我们可以看到性能又往上提高了近6倍。
因此,我们在使用pandas进行计算的时候,如果可以使用内置的矢量方法计算最好选用内置方法,其次可以考虑apply方法,如果对于非轴向的循环可以考虑iterrow方法。
2.数据类型优化
Pandas的内存使用率一直被大家抱怨,特别对于初学者,当机器资源不足的时候,经常会发现相比其他的数据结构,Pandas存储的数据很容易就会爆掉。
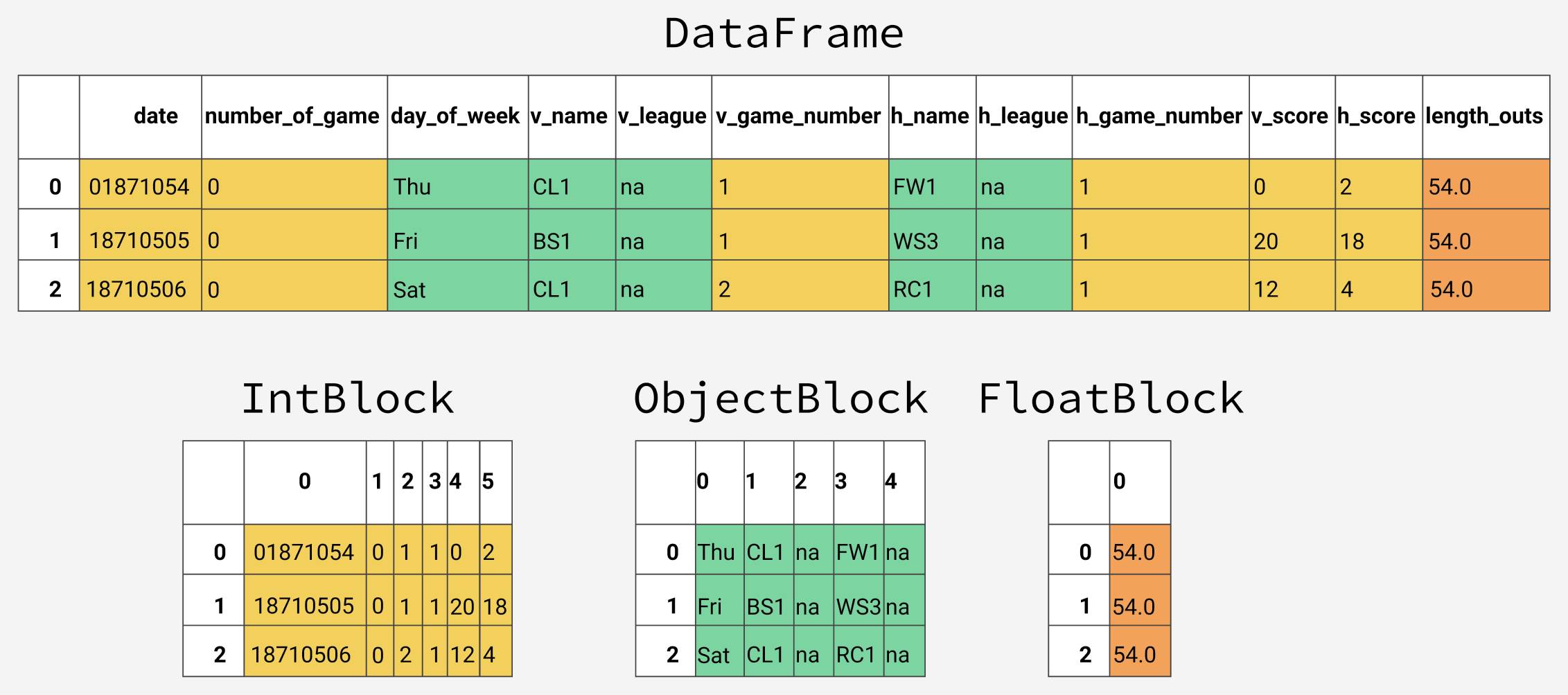
在底层的设计中,pandas按照数据类型将列分组形成数据块(blocks)。pandas使用ObjectBlock类来表示包含字符串列的数据块,用FloatBlock类来表示包含浮点型列的数据块。对于包含数值型数据(比如整型和浮点型)的数据块,pandas会合并这些列,并把它们存储为一个Numpy数组(ndarray)。Numpy数组是在C数组的基础上创建的,其值在内存中是连续存储的。基于这种存储机制,对其切片的访问是相当快的。
df.info(memory_usage='deep') |
2.1 子类型优化数值型列
pandas中的许多数据类型具有多个子类型,比如,float型就有float16、float32和float64子类型,分别使用了2、4、8个字节。
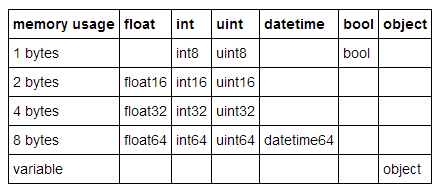
我们可以用函数pd.to_numeric()来对数值型进行向下类型转换。用DataFrame.select_dtypes来只选择特定类型列,然后我们优化这种类型,并比较内存使用量。
df_int = df.select_dtypes(include=['float']) |
输出结果float64 19703760
float32 9851920
实验表明,float32比float64整好优化了一半内存
2.2 用category类型代替object类型
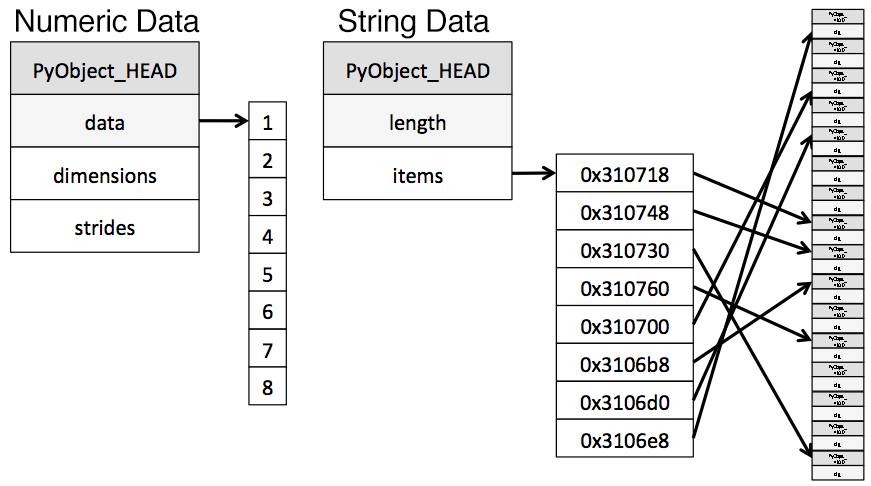
object类型用来表示用到了Python字符串对象的值,有一部分原因是Numpy缺少对缺失字符串值的支持。因为Python是一种高层、解析型语言,它没有提供很好的对内存中数据如何存储的细粒度控制。
这一限制导致了字符串以一种碎片化方式进行存储,消耗更多的内存,并且访问速度低下。在object列中的每一个元素实际上都是存放内存中真实数据位置的指针。
category类型在底层使用整型数值来表示该列的值,而不是用原值。Pandas用一个字典来构建这些整型数据到原数据的映射关系。当一列只包含有限种值时,这种设计是很不错的。当我们把一列转换成category类型时,pandas会用一种最省空间的int子类型去表示这一列中所有的唯一值。
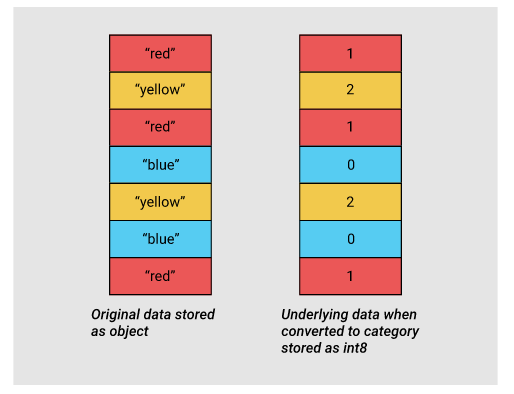
实验
输入:df_object = df.select_dtypes(include=['object'])
print(df_object.columns)
输出结果Index(['起点城市', '终点城市', '终点城市代码', '终点城市lng', '终点城市lat', '日期'], dtype='object')
输入down_cast_cols = df_object['起点城市'].astype('category')
print('before...')
print(df_object['起点城市'].memory_usage(deep=True))
print('after...')
print(down_cast_cols.memory_usage(deep=True))
输出before...
28885690
after...
659649
可以看出效果是非常明显的,压缩了近30倍的内存空间~
这种基于类型的优化我们一般在数据载入的时候就可以进行自定义了,这样即可以大大的节省内存的空间。
df_origin = pd.read_csv('输出结果_总量_迁出.csv',encoding='gbk',engine='python') |
输出结果No optimization...
147934
After optimization ....
35437
原始结果内存147M,优化后35M,内存优化了近四倍
3. 总结
对于Pands的优化还有很多,这里主要介绍三种最常用的优化方法,一种是对于数据量极大的情况,可以使用Pandas on Ray 或者 Dask 优化,第二种是对于在运算的时候采用自定义的矢量迭代函数代替for循环可以取得显著的性能提升,第三种方法是通过对存储类型的设置或转换来优化pandas内存使用。
